How to create a parsing rule
This tutorial will show you how to create a parsing rule from a simple one text log.
In this manual, we will be working with Amavis log messages. At the end of the tutorial you will find a link to download the entire parser in xml.
From the Logmanager, export a set of messages (check the boxes raw)
Beware, parsers only work with the value without the automatically detected message header.The size of the header is determined automatically by Logmanager and saved in the raw_offset field, which carries the number of characters that mark the header.
In the example below, the message header is underlined for raw_offset: 43.
Raw message:
“raw”: “<14>Jun 28 09:15:08 ipserver amavis[17394]: (17394-04) Checking: Bm-tfULasl43 [192.0.2.0] john@example.com -> paul@example.com” “raw_offset”: “43”
The parser only processes part of the message without the header. The message header is automatically cut by raw_offset for parse processing, and for the example above, the resulting message appears in the Message structure block.
(17394-04) Checking: Bm-tfULasl43 [192.0.2.0] john@example.com -> paul@example.com
For more information about the message format, please see: Format of saved message
Go to the Test message text box below the designer and copy all variants of the log you want to process.
As an example, we will take the Amavis log, where we will be interested in messages with information about allowed or blocked email messages. That is, lines containing Passed or Blocked. The messages that come to the parser will look like this:
Passed:
(02307-10) Passed CLEAN {RelayedInbound}, [192.0.2.0]:45407 <george@example.com> -> <ringo@example.com>, Queue-ID: B853420663, Message-ID: <9f580e$4kae1u@logmanager.cz>, mail_id: fsmv0C_QZesf, Hits: 5.001, size: 1496, queued_as: DA4ED220E2, 138 ms
Blocked:
(02309-09) Blocked SPAM {RejectedInbound,Quarantined}, [192.0.2.0]:4817 <barry@example.com> -> <robin@example.com>,<maurice@example.com>, Queue-ID: E96D520663, Message-ID: <9f580e$4kadc0@logmanager.cz>, mail_id: 7mUrDPQ7UuWW, Hits: 2.8, size: 1077, queued_as: 12804220E2, 113 ms
This log has predefined positions and order of each field:
- Behind the process number is information about what happened with the message:
PassedorBlocked - The following is the reason (in capital letters):
CLEAN,SPAM, etc. - Next, in curly brackets, there is action and direction:
{RelayedInbound},{RejectedInbound,Quarantined} - Then the source IP address with the port number follows:
[192.0.2.0]:45407 - Then there is the sender and the list of recipients:
<george@example.com> -> <ringo@example.com> - The following is a set of pairs of “key: value” separated by a comma:
Hits: 5.001, size: 1496,.... - At the end of the message, there is always the session duration:
138 ms
According to Amavis documentation, there may be more comma-separated addresses in the recipient field (we’ll count on it). Additionally, the public IP address may appear behind the original source IP address. The port number may not always be logged.
- We recommend using recommended standards for key naming according to the Logmanager documentation
- For clarity, it’s good to use the comment block, where you can write notes.
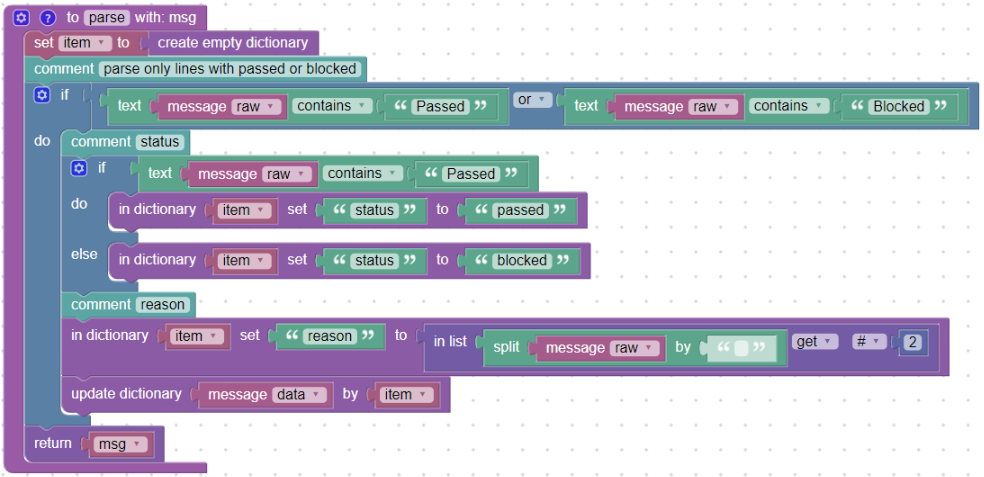
In the beginning, it is advisable to create a so-called helper dictionary (in our manual we will use a dictionary called “item”) into which we will gradually insert individual parsed fields.
At the end, we put this dictionary into the MessageData dictionary, which is a variable that we will then see in the Logmanager as msg field.
A good habit is to have each such variable (dictionary) initially defined using a block:
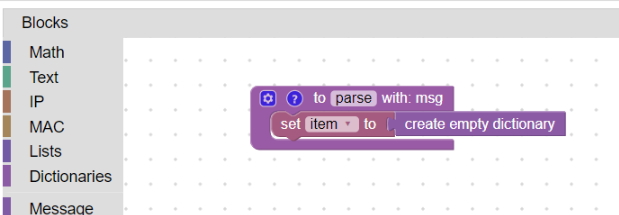
Defining the dictionary “item”
Because we only want to track “Passed” or “Blocked” messages, we create a condition and use the text_contains block to find out whether message_raw contains the word “Passed” or “Blocked”.
If no such word exists, commands within the if block are not executed and a message is sent to the Logmanager as it arrived (block return_msg). This way, you can easily filter the messages you want to work with. Of course, the condition could be extended by testing a string like “) Passed”.
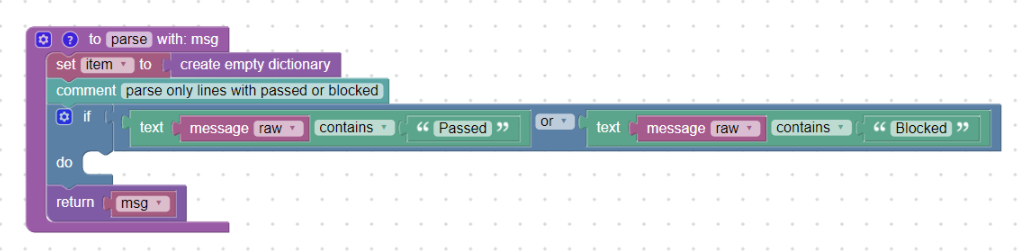
Condition for the content of “Passed” or “Blocked”
Now we can proceed to the gradual fulfillment of the “item” dictionary by individual values.
status:
Into the “status” (msg.status) we want to insert what happened - the “Passed” or “Blocked”. We also want to have this status only lowercase letters. In our created “item” dictionary, we insert the first field with the in_dictionary_set block in which we directly insert the required text “passed” or “blocked”:
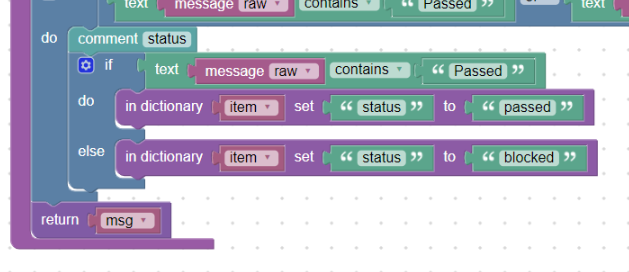
Direct insertion of text
reason:
The “status” follows the “reason” (in capital letters) why this happened. We take advantage of splitting the message into parts separated by spaces and this word will be the third in the order, see:
(02307-10) Passed CLEAN
So if we divide the message with a split_by block into the list (block in_list), the third position will be the word “CLEAN”. At the same time, we store this word into the “reason” field (msg.reason) using the in_dictionary_set block:
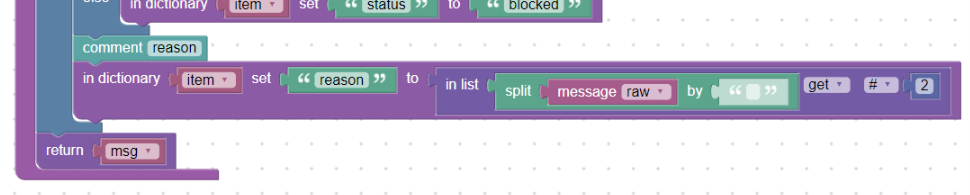
Using split_by and in_list
Positions in lists or dictionaries are numbered from zero. This means that we will get the third item in the list under number 2.
If we want to see a result in the Test output window, we need to update the MessageData main dictionary. Update it with our partially-filled “item” dictionary using update_dictionary block:

Update dictionary MessageData
At this point, we should see this result in the window Test output in the msg object:
msg: Object
reason: "CLEAN"
status: "passed"
And we will see a parser in the following form:
Continuous parser form
description:
In cases where the “reason” field is “BANNED” or “INFECTED”, this is followed by additional information in brackets, such as:
Blocked BANNED (.image,.gif,image001.gif,image001.gif)
Blocked INFECTED (Mal/BredoZp-B)
We create a condition that if the reason is “BANNED” or “INFECTED”, we will parse the next section after this word in brackets. We will then update the “item” dictionary using the search_by_regex block. We parse the text in message_raw and write a simple regular expression to the content in brackets preceded by “BANNED” or “INFECTED”:
(BANNED|INFECTED) \((?P<description>[^\)]*)\)
This will save a value in the “description” field (msg.description), which is in brackets:
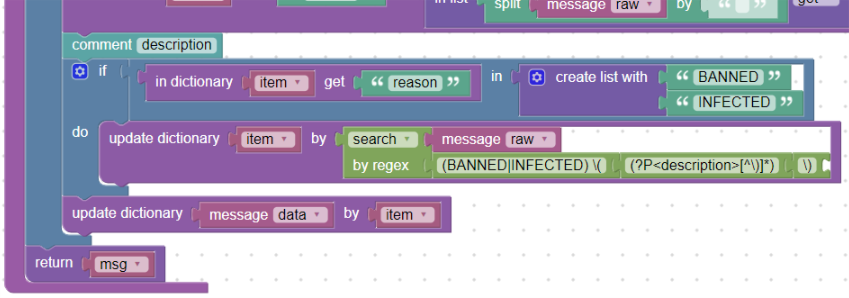
Using regular expression
direction & action:
In the next part, the text is in curly brackets. Here’s information about the action and direction. These values are combined together in one word, for example:
{RelayedOutbound}
{DiscardedOpenRelay}
{NoBounceInbound}
From the documentation for Amavis we know that the direction can be one of the options: Inbound, Outbound, OpenRelay, Internal. The word before is “action”. So we want to save the direction in the “direction” field (msg.direction) and save the action in the “action” field (msg.action).
Into the helper variable actions_part, we insert text that is in curly brackets. We will use get_substring and find_first_occurence blocks, and at the same time we trim the curly brackets “} {” off whole text (using block trim_from).
Then, we will create a list of possible directions (block create_list), which will be iterated with the foreach_item loop. If the text of the actions_part variable contains the current direction, we place a “direction” into the “item” dictionary and assign the current direction as the value.
Next, we will insert another “action” field and its value will be the first part of the field divided by block split_by (action + direction), see picture:
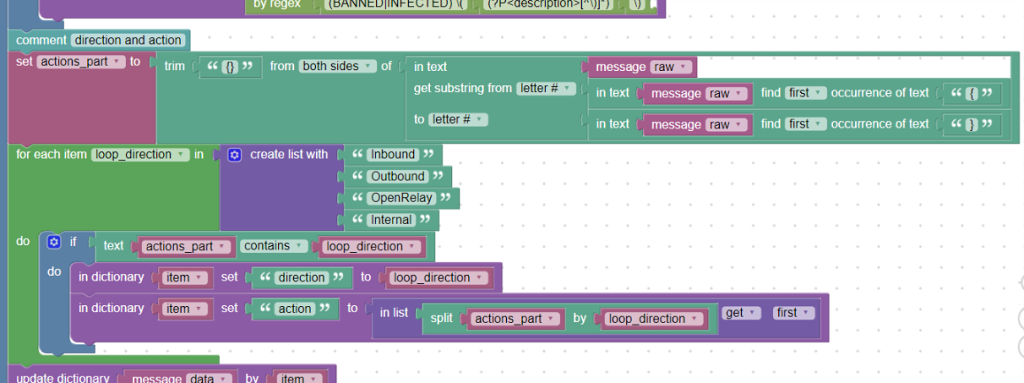
Iteration, trim, get substring
quarantined:
At the same time, the event may occur if the email has been quarantined, see for example:
(02309-09) Blocked SPAM {RejectedInbound,Quarantined}
We will want to save this in the “quarantined” (msg.quarantined) field.
In cases where this word appears in curly brackets (still stored text in helper variable “actions_part”), we create a new “quarantined” field and insert the Boolean “true” value into it:
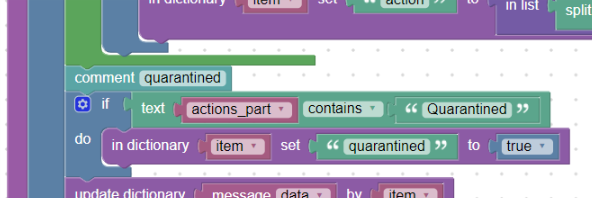
Inserting a Boolean value
ip & port:
This is followed by information about the source IP and port number:
(02309-09) Blocked SPAM {RejectedInbound,Quarantined}, [192.0.2.0]:4817
(17558-02) Passed CLEAN {RelayedOutbound}, LOCAL [192.0.2.0]
The IP address is in square brackets, followed by a port number behind the colon. In the “src_ip” (msg.src_ip) field, we save the source ip address. In the “src_port” (msg.src_port) field, we store the port number (if any).
We want both fields to be normalized: msg.src_ip as data type ip and msg.src_port as data type integer.
The simplest way is to use the regular expression with the knowledge that after the square bracket begins the ip address. So we use the block search_by_regex. For the ip address and port number we use substitutions (block Regex assign) that will normalize the resulting values (ip and integer):

Regular expression and regex_assign
However, since the port number after the IP address may not appear, we need to delete the port number in these cases, because the parser inserts a numerical value “-1” into the “src_port” field.
We will make use of this and create a condition that if “src_port” is equal to “-1”, we remove this field (block delete) from the “item” dictionary:
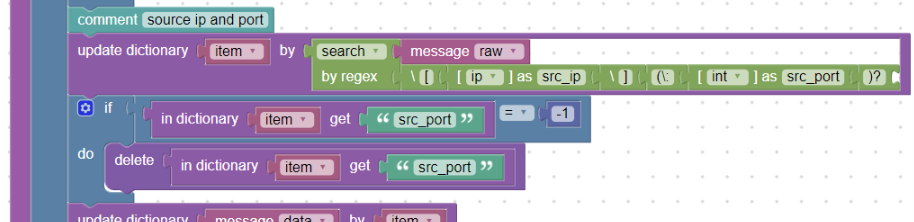
Deleting non-existent values
If you create a condition where you compare a numeric value, you have to use the block number that defines the integer data type.
from & to:
Next in the log is the information about sender and recipients.
There is always one sender, there can be more recipients, which are then separated by a comma. Email addresses are enclosed in angle brackets. There is a sequence of characters “->” between the sender and the recipient, for example:
<john@example.com> -> <paul@example.com>
or more recipients:
<barry@example.com> -> <robin@example.com>,<maurice@example.com>
We’d like to save the sender in the “from” (msg.from) field,
and the recipient in the “to” (msg.to) field that we want to store as a
list of recipients (see recommended standards).
This sequence of “->” characters can be used to create the “from”, “recipients_part” and “remain” fields using the regular expression.
The “remain” field will contain the rest of the message that we have not yet processed - this will be useful in the next steps.
These two last fields (“recipients_part” and “remain”) are temporary, we will delete them from the “item” dictionary until we get the necessary data.

Temporary fields in “item”
We create the “recipient” helper variable, which we initialize as a list. We will want to have all recipients in it and stored so as a list in the “item” dictionary.
Using the block foreach, we iterate through all recipients. We get them using the split_by block. We trim (trim) of angle brackets and commas and store one by one in the prepared helper variable “recipients”.
We will save this whole helper variable into the “to” field.
In the window Test output, we can see that msg.to has been saved
as a data type field. The original “recipients_part” field in the dictionary will be deleted:
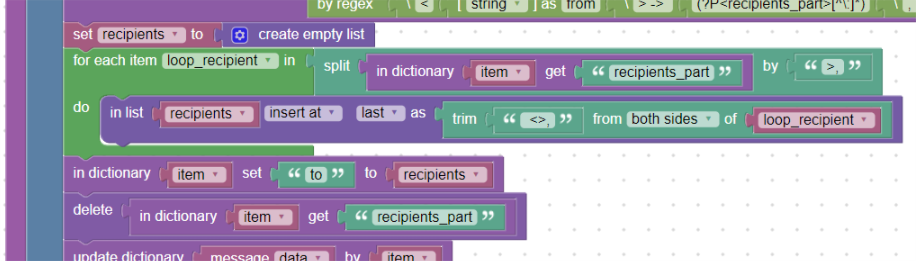
Saving fields to the dictionary
key: value:
In the next part is the section (our rest, which is now stored in the “remain” field), where each key and its values are paired together as key: value and are separated by commas. The entire log text then ends with the length in milliseconds:
Queue-ID: B853420663, Message-ID: <9f580e$4kae1u@logmanager.cz>, mail_id: fsmv0C_QZesf, Hits: 5.001, size: 1496, queued_as: DA4ED220E2, 138 ms
For these key-value cases (we do not know the exact number of keys and their names), the find_all_by block is best suited.
From the Amavis documentation, we know that the key name can only contain alphanumeric characters and hyphens and its value is a string without spaces. We use the find_all_by block and a special regular expression to insert the new fields into the “item” dictionary. We will not need the “remain” variable anymore, so we delete it using the block delete.
Regular expression for key: value can look like this:
([\w\-]+)\: (\S*)\,
We will parse the text in which we have the rest of the message in key: value pairs. (“remain” field in “item” dictionary)
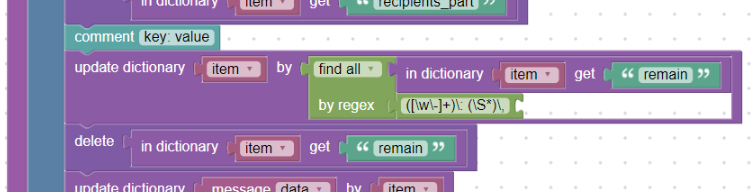
Parsing the key: value section
rename keys:
Since Logmanager field names must only contain lowercase letters, numbers, and underscores, the parser will create an “invalid_hits” field instead of the expected name for the “Hits” field.
We will then have to rename individual key names.
If we know what key names can appear in the log, we can create a helper dictionary (eg: “rename_dict”) using the create_dictionary block, where the original names of the fields will be the key and as their value will be the new name, see:
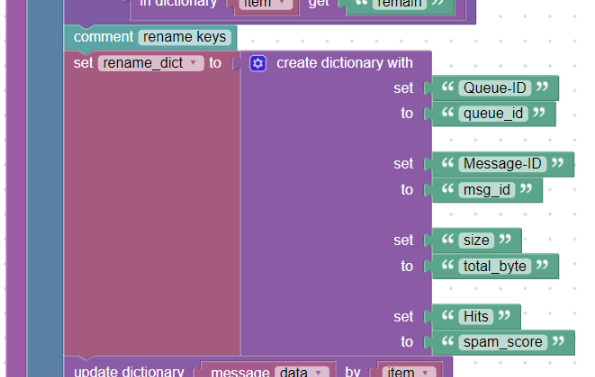
Dictionary for renaming
Then we iterate through this dictionary with a loop block foreach and if the “item” dictionary contains the name of the key from this dictionary (block in), rename it to a new name see:
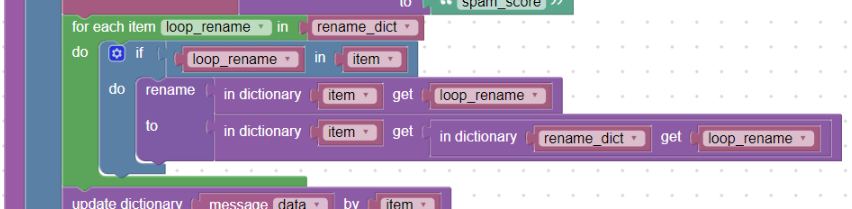
Loop “foreach” and renaming
retype keys:
At this point, we have correctly named all the keys, but their values are not normalized. Now all values are string data type. For example, if we want to change the “total*byte” field to a number (data type _integer*), we will use the retype block:
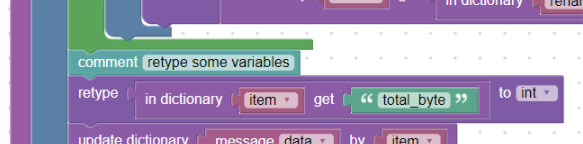
Using retype block
duration:
As the last item in the log is the total session duration in milliseconds.
We will want to save it in the “duration” field (msg.duration):
....queued_as: DA4ED220E2, 138 ms
We can either use a regular expression or a block get_substring in combination with the block find_last_occurence`. This will look for the last comma character in the message and the rest of the message will be “duration”. Then we trim the spaces and the comma at the beginning:

End of message - get substring
For clarity, it is good to use the External-Inputs option for larger blocks. Then the individual inputs of the block are placed underneath. Just right-click an empty space in the block to invoke the context menu:
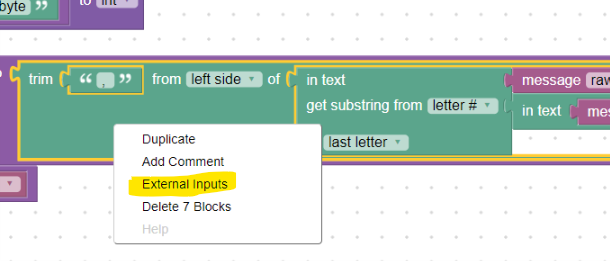
External inputs
Parser is complete. If needed, you can add user tags:
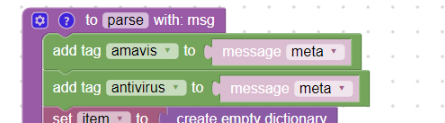
User tags
The entire sample parser in xml format can be downloaded here: Amavis parser