Návod na vytvoření parseru
Tento návod vám ukáže jakým způsobem lze vytvořit parsovací pravidlo z jednoduchého textového logu.
V tomto návodu budeme vycházet z logů ze softwaru Amavis. Na konci návodu najdete link na stažení celého parseru v xml.
Z Logmanageru vyexportujte sadu zpráv (zaškrtněte políčka raw)
Pozor, parsery pracují jen s hodnotou bez automaticky detekované hlavičky zprávy. Velikost hlavičky je automaticky určena Logmanagererem a uložena do pole raw_offset, které nese počet znaků značících hlavičku.
Na příkladu níže je hlavička zprávy podtržena pro raw_offset:43.
Raw zpráva včetně hlavičky:
„raw“: „<14>Jun 28 09:15:08 ipserver amavis[17394]: (17394-04) Checking: Bm-tfULasl43 [192.0.2.0] john@example.com -> paul@example.com“ „raw_offset“: „43“
Parserem se zpracovává pouze část zprávy bez hlavičky. Hlavička zprávy je pro zpracování parserem automaticky oříznutá o raw_offset a pro příklad uvedený výše se v bloku Message structure objeví tato výsledná zpráva:
(17394-04) Checking: Bm-tfULasl43 [192.0.2.0] john@example.com -> paul@example.com
Více informací o formátu zpráv se dozvíte zde: Formát uložené zprávy
V editaci parseru si do textového pole Test message pod blockly návrhem nakopírujte všechny varianty logu, které ze zařízení (softwaru) chodí a které hodláte zpracovávat.
Jako příklad budeme brát log z Amavis, kde nás budou zajímat zprávy s informacemi o povolených či blokovaných emailových zprávách. Tedy řádky obsahující slova Passed respektive Blocked. Zprávy, která přijdou do parseru, budou tedy vypadat například takto:
Passed:
(02307-10) Passed CLEAN {RelayedInbound}, [192.0.2.0]:45407 <george@example.com> -> <ringo@example.com>, Queue-ID: B853420663, Message-ID: <9f580e$4kae1u@logmanager.cz>, mail_id: fsmv0C_QZesf, Hits: 5.001, size: 1496, queued_as: DA4ED220E2, 138 ms
Blocked:
(02309-09) Blocked SPAM {RejectedInbound,Quarantined}, [192.0.2.0]:4817 <barry@example.com> -> <robin@example.com>,<maurice@example.com>, Queue-ID: E96D520663, Message-ID: <9f580e$4kadc0@logmanager.cz>, mail_id: 7mUrDPQ7UuWW, Hits: 2.8, size: 1077, queued_as: 12804220E2, 113 ms
Log má předem nadefinované pozice a pořadí jednotlivých polí:
- Za číslem procesu je informace o tom, co se se zprávou stalo:
PassedneboBlocked - Následuje velkými písmeny důvod:
CLEAN,SPAM, apod. - Dále ve složených závorkách akce a směr:
{RelayedInbound},{RejectedInbound,Quarantined} - Poté zdrojová ip adresa s číslem portu:
[192.0.2.0]:45407 - Pak odesílatel a seznam příjemců:
<george@example.com> -> <ringo@example.com> - Následuje sada dvojic „klíč: hodnota“ oddělené čárkou:
Hits: 5.001, size: 1496,.... - Na konci zprávy je vždy doba trvání relace v ms:
138 ms
Dle dokumentace Amavis je možné, že se v poli příjemce objeví vice adres oddělených čárkami (s tím budeme při psaní parseru počítat). Stejně tak může do logu přijít ještě veřejná ip adresa za původní zdrojovou ip adresou. Číslo portu se nemusí vždy zalogovat.
- Pojmenování jednotlivých klíčů doporučujeme používat standardní názvy z dokumentace Logmanager.
- Pro přehlednost je dobré používat blok comment, do kterého si můžete psát poznámky.
Na začátek je vhodné si vytvořit takzvaný pomocný slovník (v našem návodu budeme používat slovník s názvem „item“), do kterého budeme postupně vkládat jednotlivá rozparsovaná pole.
Na konci pak tento slovník vložíme (updatujeme) do slovníku MessageData, což je proměnná, kterou následně v Logmanager uvidíme jako pole msg.
Dobrým zvykem je si každou takovou proměnnou (slovník) nejdříve nadefinovat:
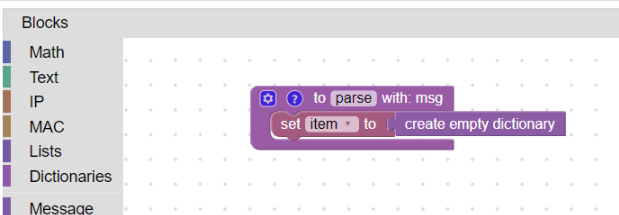
Definování slovníku item
Jelikož chceme sledovat pouze zprávy s hláškami „Passed“ nebo „Blocked“, vytvoříme podmínku a pomocí bloku text contains zjistíme, zda pole message_raw obsahuje slovo „Passed“ nebo „Blocked“.
Pokud neobsahuje, příkazy uvnitř bloku if se nevykonají a do Logmanageru se pošle zpráva tak, jak přišla (blok return_msg). Tímto způsobem lze jednoduše vyfiltrovat zprávy, se kterými chceme pracovat. Podmínka by se samozřejmě dala ještě zpřísnit tím, že by se testoval řetězec, například „) Passed“.
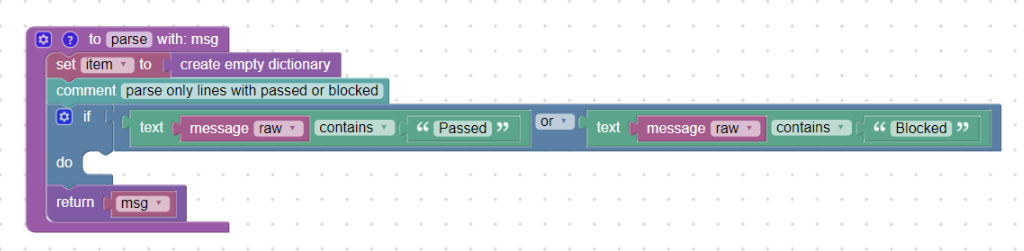
Podmínka na obsah slov „Passed“ nebo „Blocked“
Nyní již můžeme přistoupit k postupnému plnění slovníku „item“ jednotlivými hodnotami.
status:
Do políčka „status“ (msg.status) budeme chtít vložit co se stalo - tedy „Passed“ nebo „Blocked“. Zároveň tento status chceme pouze malými písmeny. Do našeho vytvořeného slovníku „item“ vložíme první pole blokem in_dictionary_set do kterého přímo vložíme požadovaný text „passed“ nebo „blocked“:
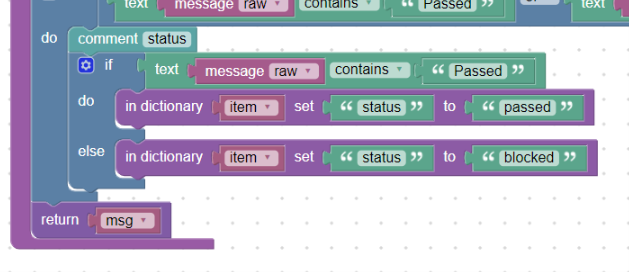
Přímé vložení textu
reason:
Za statusem je velkými písmeny důvod proč se tak stalo. Využijeme toho, že rozdělíme-li zprávu na části oddělené mezerami, bude toto slovo jako třetí položka od začátku, viz:
(02307-10) Passed CLEAN
Pokud tedy zprávu rozdělíme blokem split_by do seznamu (blok in_list) podle mezer, tak třetí pozice bude slovo „CLEAN“. Zároveň toto slovo uložíme do políčka „reason“ (msg.reason) opět blokem in_dictionary_set:
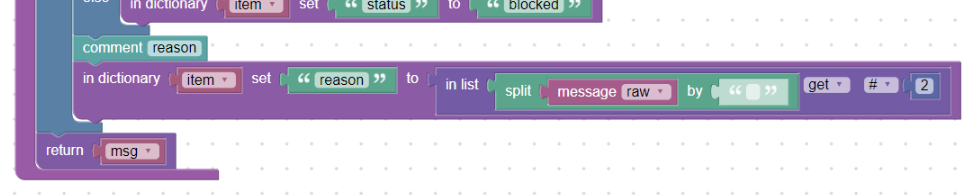
Využití split_by a in_list
Pozice v seznamech či slovnících jsou číslovány od nuly. Znamená to, že třetí položku v seznamu dostaneme pod číslem 2.
Abychom již viděli nějaký výsledek v okně Test output musíme udělat blokem update_dictionary update hlavního slovníku MessageData. Rozšíříme jej naším, zčásti naplněným slovníkem „item“:

Update slovníku MessageData
V tuto chvíli bychom měli v okně Test output vidět v objektu msg tento výsledek:
msg: Object
reason: "CLEAN"
status: "passed"
A parser v průběžné podobě asi takto:
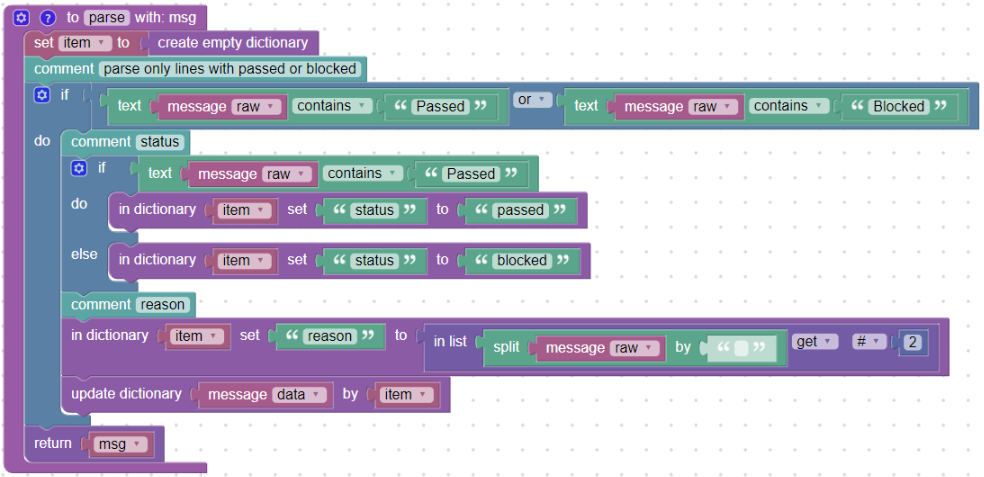
Průběžná podoba parseru
description:
V případech, kdy políčko „reason“ je „BANNED“ nebo „INFECTED“, je za tímto slovem v závorce doplňující informace, např.:
Blocked BANNED (.image,.gif,image001.gif,image001.gif)
Blocked INFECTED (Mal/BredoZp-B)
Vytvoříme podmínku, že pokud je důvod „BANNED“ nebo „INFECTED“ budeme parsovat další část za tímto slovem v závorce. Uděláme tedy update slovníku „item“, na který použijeme blok search_by_regex. Parsovat budeme text v message_raw a napíšeme jednoduchý regulární výraz na obsah mezi závorkami, kterým předchází text BANNED nebo INFECTED:
(BANNED|INFECTED) \((?P<description>[^\)]*)\)
Tímto uložíme do slovníku „item“ do pole s názvem „description“ (msg.description) hodnotu, která je v závorce:
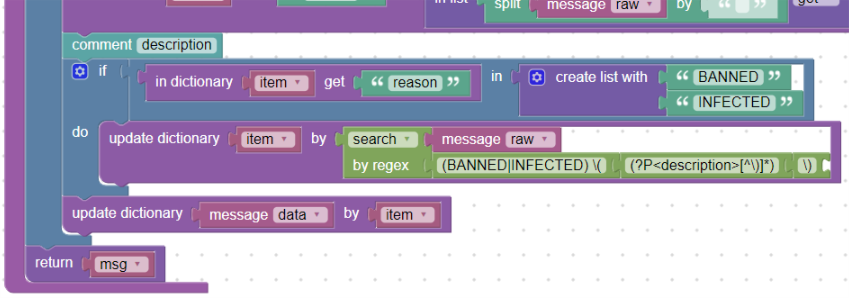
Použití regulárního výrazu
direction & action:
Další částí je text ve složených závorkách. Zde jsou informace o provedených akcích a směru datového toku, přičemž hodnoty pro akci a směr jsou spojené dohromady v jedno slovo, například:
{RelayedOutbound}
{DiscardedOpenRelay}
{NoBounceInbound}
Z dokumentace pro Amavis víme, že směr je jedna z možností: Inbound, Outbound, OpenRelay, Internal. Slovo před tímto směrem je akce. Budeme tedy chtít do políčka „direction“ (msg.direction) uložit směr a do políčka „action“ (msg.action) provedenou akci.
Do pomocné proměnné actions_part si vložíme text, který je ve složených závorkách. Použijeme na to bloky get_substring a blok find_first_occurence, a zároveň tento celý text ořízneme (blok trim_from) o složené závorky „}{„.
Poté si vytvoříme seznam možných směrů (blok create_list), který projdeme cyklem foreach_item. Pokud text pomocné proměnné actions_part (text mezi složenými závorkami) obsahuje aktuální směr, vložíme do slovníku „item“ políčko „direction“ a jako hodnotu přiřadíme právě procházenou položku.
Následně vložíme další políčko „action“ a jeho hodnotou, kterou dostaneme jako první část z pole rozděleného blokem split_by (akce+směr), viz obrázek:
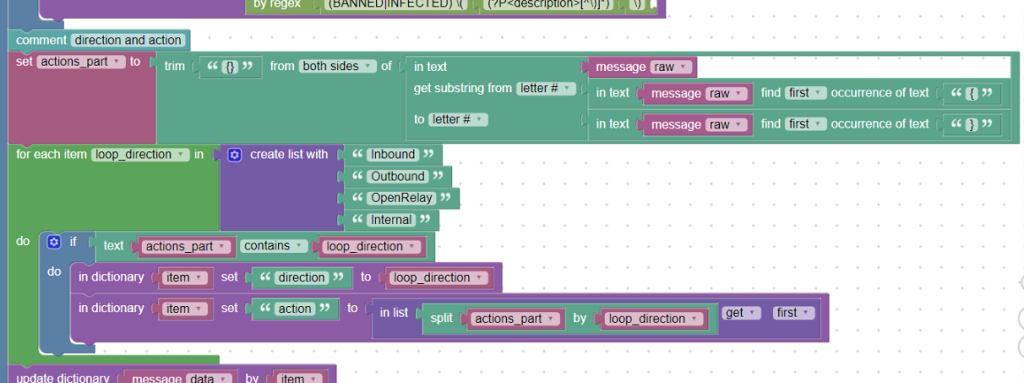
Procházení cyklem, trim, get substring
quarantined:
U akce zároveň může nastat případ, že byl email přesunut do karantény (Quarantined), viz například:
(02309-09) Blocked SPAM {RejectedInbound,Quarantined}
To budeme chtít sledovat v políčku „quarantined“ (msg.quarantined).
V případech, kdy se toto slovo objeví ve složených závorkách (stále uchovaný text v pomocné proměnné „actions_part“), vytvoříme nové políčko „quarantined“ ve slovníku „item“ a vložíme do něj boolean hodnotu „true“:
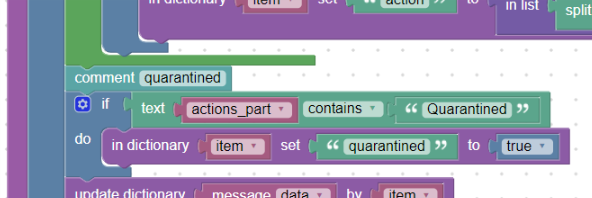
Vložení boolean hodnoty
ip & port:
Dále v textu zprávy následují informace o zdrojové ip a čísla portu:
(02309-09) Blocked SPAM {RejectedInbound,Quarantined}, [192.0.2.0]:4817
(17558-02) Passed CLEAN {RelayedOutbound}, LOCAL [192.0.2.0]
Ip adresa je v hranatých závorkách a může za ní být za dvojtečkou číslo portu. Do políčka „src_ip“ (msg.src_ip) vložíme zdrojovou ip a do políčka „src_port“ (msg.src_port) číslo portu (pokud bylo zalogováno).
Obě tato políčka budeme chtít uložit rovnou normalizované: msg.src_ip jako datový typ ip a msg.src_port jako datový typ integer.
Nejjednodušší bude použít regulární výraz s tím vědomím, že hranatá závorka uvozuje ip adresu. Použijeme tedy blok search_by_regex a v něm pro ip adresu a číslo portu substituce (blok Regex assign), které se nám postarají o normalizování výsledné hodnoty (ip a integer):

Regulární výraz a regex_assign
Jelikož se ale číslo portu za ip adresou objevit nemusí, musíme v těchto případech číslo portu následně vymazat. Parser v těchto případech vloží do políčka „src_port“ numerickou hodnotu „-1“.
Toho využijeme a vytvoříme podmínku, že pokud je pole „src_port“ rovno hodnotě „-1“, toto pole odstraníme (blokem delete) ze slovníku „item“:
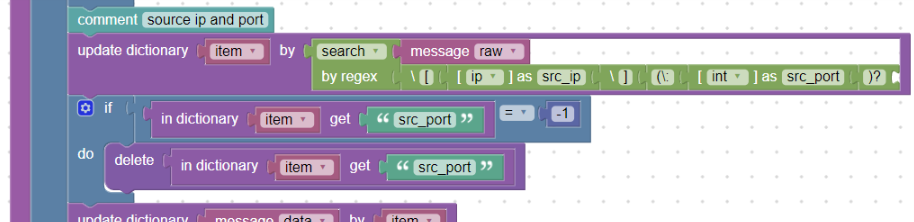
Vymazání neexistující hodnoty
Pokud vytváříte podmínku, kde porovnáváte numerickou hodnotu, musíte pro porovnání použít blok number, který definuje datový typ integer.
from & to:
Dále jsou v logu informace o odesílateli a příjemcích.
Odesílatel je vždy jeden, příjemců může být více a jsou poté oddělení čárkou. Emailové adresy jsou uzavřené ve špičatých závorkách. Mezi odesílatelem a příjemcem je pak sled znaků „->“ např.:
<john@example.com> -> <paul@example.com>
nebo více příjemců:
<barry@example.com> -> <robin@example.com>,<maurice@example.com>
Odesílatele budeme chtít ukládat do políčka „from“ (msg.from). A příjemce do políčka „to“ (msg.to), které budeme chtít ukládat jako seznam příjemců (viz doporučené standardy).
Sled znaků „->“ můžeme využít a vytvořit si ve slovníku „item“ regulárním výrazem políčka „from“, „recipients_part“ a „remain“.
Políčko „from“ bude obsahovat odesílatele, v políčku „recipients_part“ budeme mít všechny příjemce a zároveň si vytvoříme i políčko „remain“, to bude obsahovat zbytek zprávy, který ještě nemáme zpracovaný - to se nám bude hodit v dalších krocích.
Tato dvě poslední políčka berme jako dočasná. Až z nich vytáhneme potřebná data, vymažeme je ze slovníku „item“.

Dočasná políčka v item
Vytvoříme si pomocnou proměnnou „recipients“, kterou inicializujeme jako list (seznam). V ní budeme chtít mít všechny příjemce a takto také uložené jako seznam ve slovníku „item“.
V bloku foreach projdeme postupně všechny příjemce, které získáme blokem split_by, ořízneme (blok trim) o špičaté závorky a čárky a uložíme jednoho po druhém do připravené pomocné proměnné „recipients“.
Celou tuto proměnou vložíme do slovníku „item“ do políčka „to“. V okně Test output rovnou vidíme, že se políčko msg.to uložilo jako datový typ pole. Původní políčko „recipients_part“ ze slovníku smažeme:
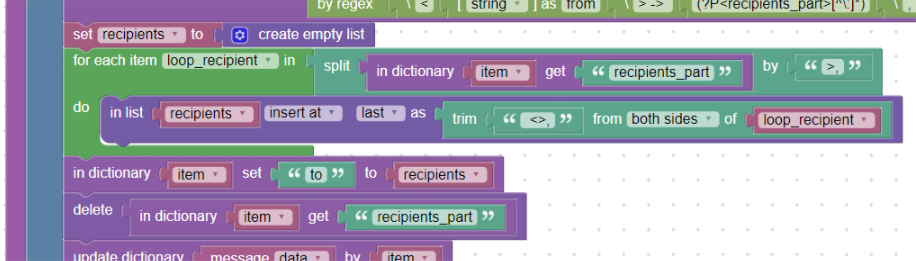
Ukládání polí do slovníku
key: value:
V další části je sekce (náš zbytek, který je nyní uložen v políčku „remain“), kde jsou jednotlivé klíče a jejich hodnoty vzájemně párovány jako key: value a jsou mezi sebou oddělené čárkami. Celý text logu potom končí délkou trvání v milisekundách:
Queue-ID: B853420663, Message-ID: <9f580e$4kae1u@logmanager.cz>, mail_id: fsmv0C_QZesf, Hits: 5.001, size: 1496, queued_as: DA4ED220E2, 138 ms
Na key-value případy (většinou neznáme přesný počet a názvy klíčů) se nejlépe hodí blok find_all_by.
Z dokumentace Amavis víme, že název klíče obsahuje pouze alfanumerické znaky a pomlčku a jeho hodnota je řetězec bez mezery. Můžeme tedy pomoci bloku find_all_by a speciálního regulárního výrazu vložit do slovníku „item“ tato nová políčka. Proměnnou „remain“ už poté nebudeme potřebovat a proto ji vymažeme pomocí bloku delete.
Regulární výraz pro key: value může vypadat například takto:
([\w\-]+)\: (\S*)\,
Parsovat budeme text, ve kterém máme zbytek zprávy a právě tyto hodnoty key: vlaue, tedy políčko „remain“ ze slovníku „item“:
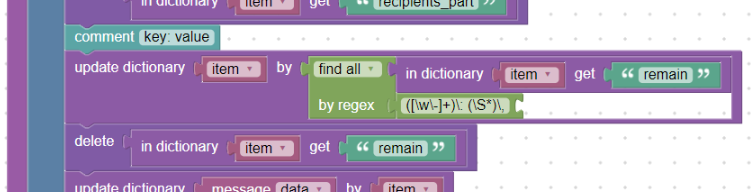
Parsování sekce key: value
rename keys:
Vzhledem k tomu, že v Logmanageru musí názvy políček obsahovat pouze malá písmena, čísla a podtržítka, parser nám v tuto chvíli vytvoří místo očekávaného názvu políčka „Hits“, pole „invalid_hits“.
Budeme tedy muset jednotlivé názvy klíčů přejmenovat.
Pokud víme, jaké názvy klíčů se mohou v logu objevit, můžeme si vytvořit pomocný slovník např.: „rename*dict“ blokem create_ dictionary, kde jako klíč budou původní názvy políček a jako jejich hodnota bude potřebný název nový viz:
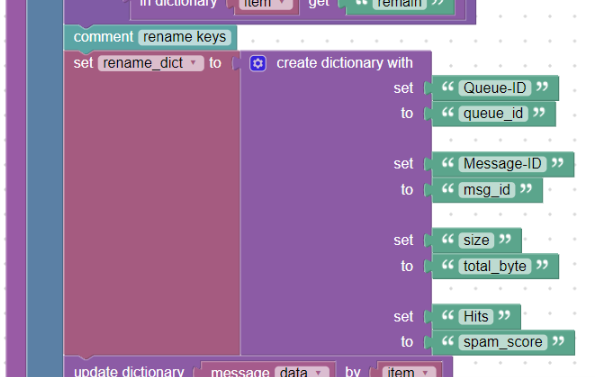
Slovník pro přejmenování
Poté projdeme tento slovník cyklem bloku foreach a pokud slovník „item“ obsahuje název klíče z tohoto slovníku (blok in), přejmenujeme jej na nový název viz:
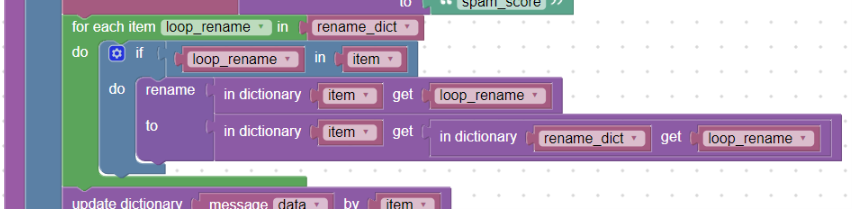
Cyklus „foreach“ a přejmenování
retype keys:
V tuto chvíli máme správně pojmenované všechny klíče z rename, ale jejich hodnoty nejsou normalizovány. Nyní jsou všechny datového typu String. Chceme-li například políčko „total*byte“ přetypovat na číslo (datový typ integer) použijeme blok retype:
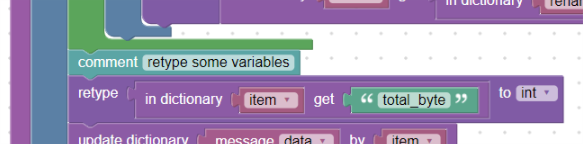
Použití bloku retype
duration:
Jako poslední položku logu máme celkovou dobu trvání relace v milisekundách. Budeme ji chtít jako celý text i s jednotkou vložit do políčka „duration“ (msg.duration):
....queued_as: DA4ED220E2, 138 ms
Můžeme využít buď regulární výraz, nebo například blok get_substring v kombinaci s blokem find_last_occurence, který bude hledat poslední čárku, a zbytek zprávy už bude „duration“, kterou ještě ořízneme o mezery a čárku na začátku (blok trim):

Konec zprávy - get substring
Pro přehlednost je dobré používat u větších bloků možnost External-Inputs, kde se jednotlivé vstupy bloku řadí pod sebe. Stačí kliknout pravým tlačítkem na prázdné místo v bloku a vyvolat tím kontextovou nabídku:
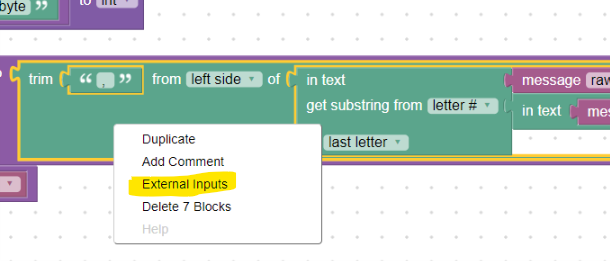
Přehlednost parseru
Tímto je parser hotov. V případě potřeb jej lze doplnit o uživatelské tagy:
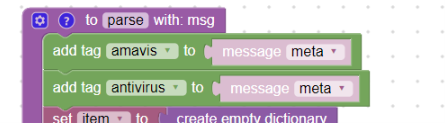
Uživatelské tagy
Celý ukázkový parser ve formátu xml si lze stáhnout zde: Amavis parser