Architektura Logmanageru
Tato stránka poskytuje architektonické detaily Logmanager 4 a popisuje, jak jsou logy a události zpracovávány a ukládány. Naleznete zde vysvětlení kompletní pipeline pro zpracování logů, od jejich příjmu až po uložení.
Níže uvedený diagram ukazuje zjednodušený pohled na tok logů systémem Logmanager:
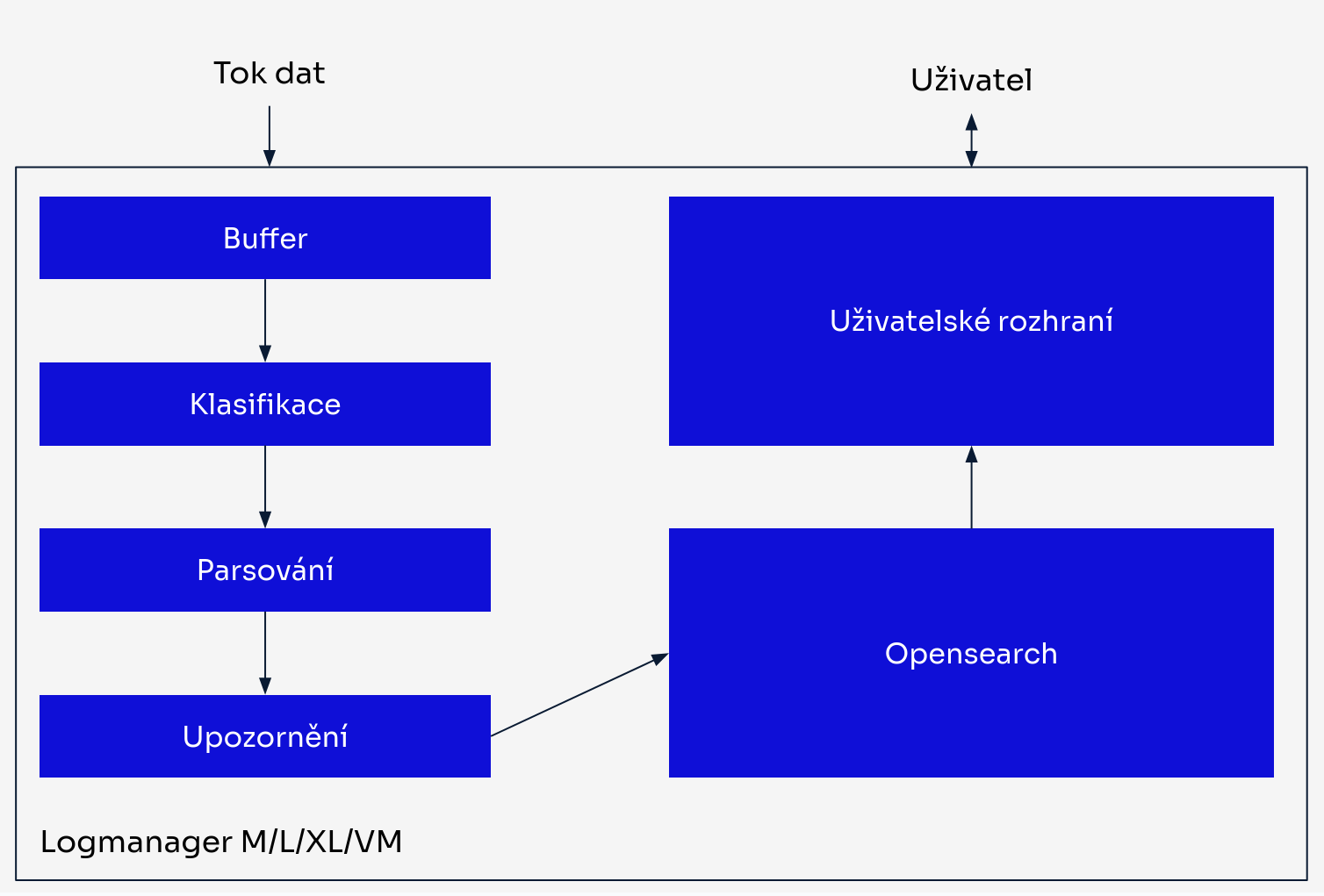
Tok logů v Logmanageru
-
Příjem dat: Logy jsou přijímány Logmanagerem z různých zdrojů.
-
Buffer: Každý příchozí log je uložen do bufferu (vyrovnávací paměti) a je mu přiřazeno časové razítko (
@timestamp). Hlavním účelem bufferu je poskytnout dodatečnou vrstvu zabezpečení pro vaše data. V případě přetížení systému jsou všechny logy bezpečně uloženy zde a čekají, až na ně přijde řada se zpracováním. Pokud se buffer blíží své maximální kapacitě, je odesláno e-mailové upozornění operátorovi, aby indikovalo potenciální přetížení Logmanageru. -
Klasifikace: Tento proces určuje, který parser má daný log zpracovat. Během klasifikace jsou automaticky generována a k logu připojena metadata. Metadata pomáhají identifikovat původ logu. Příklady zahrnují:
meta.src.ip- IP adresa zařízení, které log vygenerovalometa.src.transport- síťový port Logmanageru, na kterém byl log přijatmeta.parser- parser, který bude log zpracovávat v dalším kroku
Logmanager poskytuje vestavěná klasifikační pravidla pro různé zdroje logů, což vám pomůže rychle začlenit vaše prostředí. Klasifikaci můžete také vyladit vytvořením vlastních klasifikačních konfigurací podle vašich potřeb. Více informací naleznete v sekci Klasifikace.
-
Parsování: Logy jsou zpracovány parserem vybraným v předchozím kroku. Původní data logu jsou extrahována a mapována na jednotlivá pole podle logiky parseru. Více informací naleznete v sekci Parsery.
-
Upozornění: V této fázi jsou vyhodnocována a spouštěna korelační pravidla a upozornění. Upozornění mohou také obohacovat logy vytvářením nových dat zprávy bez úpravy parseru. Při odeslání e-mailového upozornění systém automaticky přiřadí štítek
notified(upozorněno), který se používá k zobrazení všech odeslaných upozornění v dashboardu Alerted Events. Více informací naleznete v sekci Pravidla. -
Uložení v OpenSearch: Logy jsou uloženy v databázi OpenSearch ve formátu JSON, připravené k analýze a vizualizaci.
-
Uživatelské rozhraní: Uživatelské rozhraní poskytuje možnosti pro vyhledávání, analýzu, konfiguraci a správu zařízení Logmanager.
-
Zachování původní podoby logů: Bez ohledu na výsledky klasifikace nebo parsování je každý log uložen v databázi ve své původní podobě v poli
raw. Navíc neparsované logy budou uloženy do indexuunparsed. -
Neměnné úložiště: Databáze je navržena tak, aby zabránila úpravám nebo smazání uložených logů, což zajišťuje integritu dat a shodu s předpisy (compliance).
-
Generování časových razítek: Pole
@timestampje generováno na základě toho, kdy log dorazí do bufferu Logmanageru (čas příjmu). Pro zajištění důvěryhodnosti dat Logmanager nespoléhá na žádné časové razítko uvedené v hlavičce nebo těle logu.
Logmanager 4 zavádí zásadně odlišný přístup k indexaci ve srovnání s verzí 3. Tato sekce vysvětluje základní koncepty indexace a popisuje architektonická vylepšení, která přinášejí lepší výkon a efektivnější správu logů.
Pochopení indexů je nezbytné pro docenění architektonických změn v Logmanageru 4.
Index je sbírka dokumentů, podobná databázové tabulce, optimalizovaná pro rychlé vyhledávání a analýzu. Každý dokument je sada párů klíč-hodnota (polí).
Rozdělení je následující:
- Dokument je jeden záznam, jako je objekt JSON. Když log vstoupí do systému, stane se dokumentem v rámci indexu.
- Index je seskupení souvisejících dokumentů — něco jako tabulka v databázi.
- Protože seskupujeme související dokumenty, budete mít v systému obvykle více indexů.
- Způsob, jakým jsou dokumenty seskupovány, závisí na vaší strategii indexace.
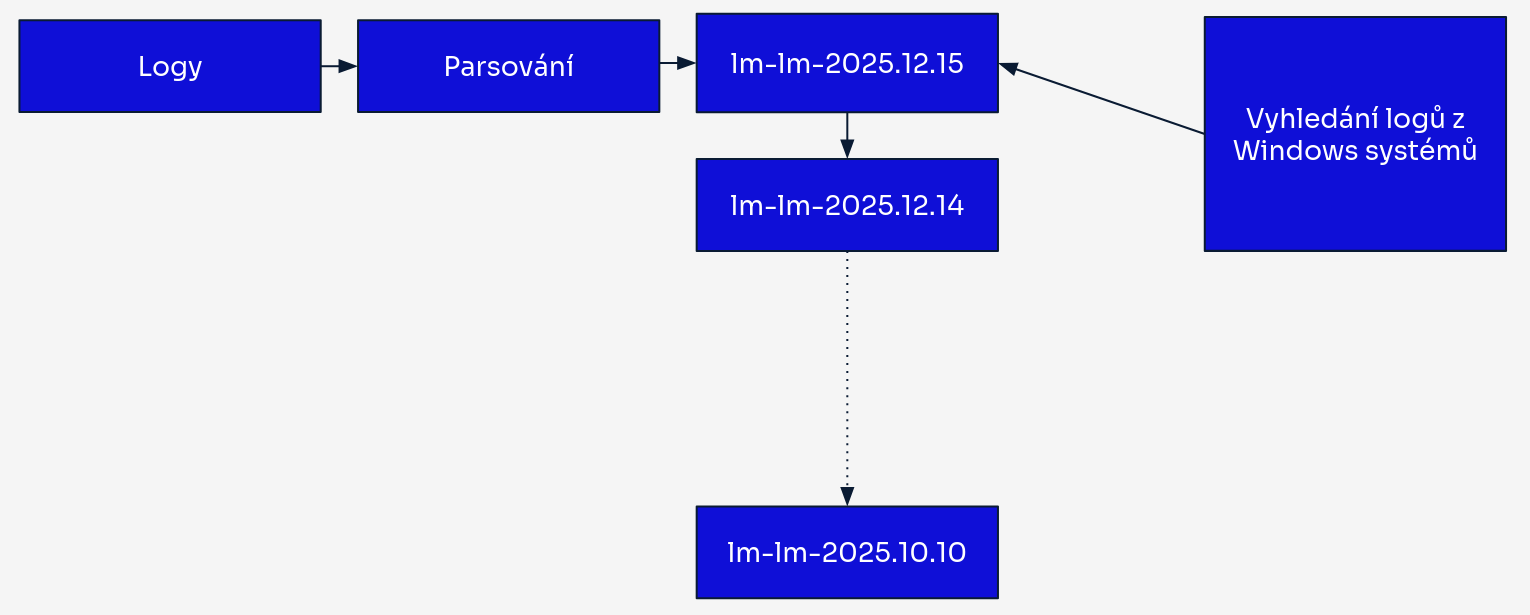
Strategie indexace Logmanager 3
V Logmanageru 3 byly logy ze všech zdrojů zpracovány příslušnými parsery a poté nahrány do jediného denního indexu. Každý log vygenerovaný během 24hodinového období skončil ve stejném indexu bez ohledu na jeho zdroj nebo typ.
Například dne 15. ledna 2024 byly všechny logy — ať už z Windows serverů, firewallů, Linux systémů nebo jakéhokoli jiného zdroje — uloženy společně v indexu s názvem lm-lm-2024.01.15.
Tento přístup založený na čase fungoval adekvátně pro menší prostředí, ale s rostoucím nasazením představoval několik výzev:
-
Výkon vyhledávání: Při hledání specifických logů (např. Windows Event logy) musel vyhledávací engine procházet celodenní objem heterogenních dat ze všech zdrojů. Ve velkých nasazeních s denními indexy o velikosti 300 GB+ to vedlo k pomalým odezvám na dotazy.
-
Vícedenní vyhledávání: Vyhledávání v delších časových úsecích znásobovalo problémy s výkonem, protože engine musel skenovat více masivních denních indexů.
-
Neefektivita zdrojů: I úzce zaměřená vyhledávání cílící na specifické typy logů spotřebovávala značné prostředky clusteru skenováním irelevantních dat.
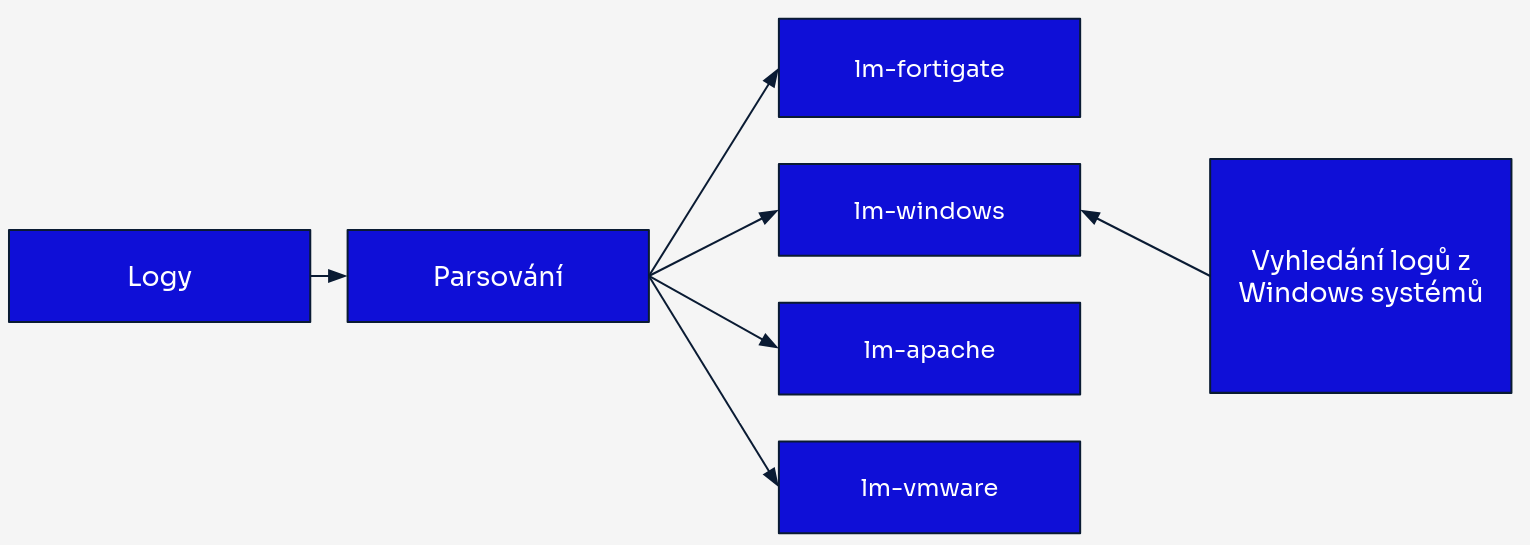
Strategie indexace Logmanager 4
Logmanager 4 řeší tato omezení pomocí indexace založené na parserech. Jedná se o strategii, která seskupuje logy podle parseru, který je zpracoval, nikoli podle času příjmu.
Každý parser nyní zapisuje do svého vlastního vyhrazeného indexu. Například:
- Windows logy zpracované parserem
lm-windowsjsou uloženy v indexulm-windows. - Firewall logy zpracované parserem
lm-linux-iptablesjsou uloženy v indexulm-linux-iptables. - Linux logy zpracované parserem
lm-linuxjsou uloženy v indexulm-linux.
Rychlejší vyhledávání: Při hledání Windows logů se vyhledávací engine dotazuje pouze indexu lm-windows a obchází všechny ostatní typy logů. Tento cílený přístup výrazně zkracuje dobu vyhledávání, zejména v prostředích s různorodými zdroji logů.
Lepší využití zdrojů: Dotazy spotřebovávají méně prostředků clusteru, protože skenují pouze relevantní indexy, což ponechává více kapacity pro souběžná vyhledávání a další operace.
Eliminace konfliktů v mapování: Každý parser má svůj vlastní index s vyhrazeným mapováním polí, což zabraňuje konfliktům polí, ke kterým mohlo docházet, když různé typy logů sdílely jeden index.
Lepší škálovatelnost: Přidání nových zdrojů logů vytváří nové indexy bez dopadu na ty stávající, což usnadňuje škálování a údržbu systému.
Následující možnosti jsou plánovány pro budoucí vydání po verzi 4.1.x
Granulární správa indexů: Indexace založená na parserech umožní konfigurace na míru pro jednotlivé typy logů:
- Vlastní retenční politiky (např. firewall logy na 90 dní, auditní logy na 7 let).
- Optimalizované nastavení alokace shardů a replikace.
- Politiky správy životního cyklu indexů založené na kritičnosti dat.
Pro ilustraci rozdílu ve výkonu uvažujme vyhledávání neúspěšných přihlášení do systému Windows za posledních 7 dní:
Přístup LM3: Vyhledávací engine skenuje 7 denních indexů, z nichž každý může obsahovat stovky gigabajtů smíšených typů logů, a poté filtruje události přihlášení do systému Windows.
Přístup LM4: Vyhledávací engine se dotazuje pouze indexu lm-windows pokrývajícího posledních 7 dní a prohledává mnohem menší, homogenní datovou sadu obsahující pouze logy Windows.
Logmanager 4 využívá automatickou správu indexů k udržení optimálního výkonu systému, efektivity úložiště a integrity dat. Indexy na pozadí procházejí několika fázemi životního cyklu — od vytvoření přes optimalizaci až po případné smazání — a to vše bez nutnosti manuálního zásahu.
Tento automatizovaný přístup zajišťuje, že:
- Úložné prostředky jsou využívány efektivně.
- Výkon vyhledávání zůstává konzistentní.
- Režie na údržbu systému je minimální.
- Jsou vynucovány politiky retence (uchovávání) dat.
Indexy jsou vytvářeny dynamicky s tím, jak jsou do Logmanageru připojovány nové zdroje logů.
Když log dorazí do Logmanageru, proběhne následující sekvence:
- Klasifikace a parsování: Log je klasifikován a je mu přiřazen parser prostřednictvím pole
meta.parser. - Identifikace parseru: Systém zkontroluje pole
meta.parserv metadatech logu. - Kontrola indexu: Logmanager ověří, zda pro tento parser již existuje index.
- Vytvoření indexu: Pokud index neexistuje, automaticky se vytvoří nový s příslušným názvem na základě pole
meta.parser. - Nahrání dokumentu: Zparsovaný dokument logu je zapsán do indexu.
Tento přístup vytváření “just-in-time” znamená, že před přidáním nových zdrojů logů nikdy nemusíte předkonfigurovat indexy. Systém se automaticky přizpůsobí vašemu prostředí.
Logmanager 4 dodržuje konzistentní vzor pojmenování, díky kterému jsou indexy snadno identifikovatelné a spravovatelné:
- Vestavěné parsery:
<název-parseru>-000001(např.lm-windows-000001,lm-firewall-000001,lm-linux-000001) - Vlastní uživatelské parsery:
lm-user-<název-parseru>-000001(např.lm-user-my-app-000001,lm-user-custom-device-000001) - Neparsované logy: Uloženy ve vyhrazeném indexu
unparsed-000001pro logy, které nebylo možné úspěšně klasifikovat nebo zparsovat.
Číselná přípona (-000001, -000002, atd.) označuje sekvenční číslo rolloveru, které se zvyšuje pokaždé, když dojde k překlopení indexu.
Číselné přípony nejsou z uživatelského pohledu viditelné. V uživatelském rozhraní uvidíte pouze název indexu bez přípony. Například:lm-user-my-appnebolm-windows.
Při vytváření nového indexu Logmanager automaticky aplikuje:
- Mapování polí specifická pro daný typ parseru, což zajišťuje uložení dat se správnými datovými typy.
- Nastavení indexu optimalizovaná pro očekávaný objem logů a vzory dotazů.
- Politiky životního cyklu, které řídí chování rolloveru a retence.
Rollovery jsou kritickým mechanismem pro udržení výkonu systému a efektivní správu úložiště. Místo toho, aby indexy rostly donekonečna, Logmanager je při dosažení předdefinovaných prahových hodnot rozděluje na spravovatelné segmenty.
Rollover indexu se automaticky spustí, když je splněna kterákoliv z těchto podmínek:
- Prahová hodnota velikosti: Index dosáhne velikosti 40 GB.
- Prahová hodnota stáří: Index je starý 30 dní.
Tyto prahové hodnoty jsou navrženy tak, aby vyvažovaly výkon vyhledávání, efektivitu úložiště a provozní režii.
Když je spuštěn rollover, proběhne následující sekvence:
- Inicializace rolloveru: Systém detekuje, že index splnil podmínku pro rollover (např.
lm-windows-000001dosáhne 40 GB). - Vytvoření nového indexu: Vytvoří se nový index se zvýšenou příponou (např.
lm-windows-000002). - Aktualizace indexu pro zápis: Nový index se stává indexem pro zápis (write index) — všechny nové dokumenty pro tento parser se nyní zapisují do
lm-windows-000002. - Přechod předchozího indexu: Předchozí index (
lm-windows-000001) se přepne do režimu pouze pro čtení (read-only) a již nepřijímá nová data. - Kontinuita vyhledávání: Oba indexy zůstávají prohledávatelné — dotazy automaticky zahrnují všechny relevantní indexy pro poskytnutí kompletních výsledků.
Rollovery poskytují několik důležitých výhod:
- Konzistentní výkon: Menší indexy poskytují rychlejší odezvy vyhledávání ve srovnání s monolitickými indexy.
- Efektivní mazání: Retenční politiky mohou mazat celé překlopené indexy atomicky, což je mnohem rychlejší než mazání jednotlivých dokumentů.
- Paralelní zpracování: Menší segmenty indexů lze během vyhledávání zpracovávat paralelně, což zlepšuje propustnost dotazů.
Uvažujme prostředí Windows s vysokým objemem dat generující 5 GB logů denně:
- Den 1-8: Logy se hromadí v
lm-windows-000001(40 GB dosaženo 8. den). - Den 8: Spuštěn rollover; vytvořen
lm-windows-000002, který se stává indexem pro zápis. - Den 8:
lm-windows-000001přesunut do warm storage (pokud je k dispozici). - Den 9-16: Logy se hromadí v
lm-windows-000002. - Den 16: Další rollover; vytvořen
lm-windows-000003. - Vyhledávání: Dotazy na “posledních 30 dní” automaticky zahrnují
lm-windows-000001,lm-windows-000002alm-windows-000003.
Logmanager implementuje automatické retenční politiky, aby zabránil vyčerpání disku a udržel stabilitu systému. Když se kapacita úložiště blíží limitům, systém inteligentně odstraňuje nejprve nejstarší data.
Logmanager používá retenci založenou na mezních hodnotách (watermark) vázaných na využití disku OpenSearch:
- Low Disk Watermark (~85 % využití disku): OpenSearch přestane na uzel alokovat nové shardy.
- High Disk Watermark (~90 % využití disku): OpenSearch se pokusí relokovat shardy pryč z uzlu.
- Flood Stage Watermark (~95 % využití disku): Indexy se přepnou do režimu pouze pro čtení, aby se zabránilo úplnému vyčerpání disku.
Když je dosaženo Low Disk Watermark, aktivuje se retenční politika Logmanageru:
- Identifikace nejstaršího indexu: Systém identifikuje nejstarší překlopené indexy napříč všemi parsery.
- Mazání: Jsou smazány celé indexy (nikoli jednotlivé dokumenty), počínaje těmi nejstaršími.
- Uvolnění místa: Mazání pokračuje, dokud využití disku neklesne pod mezní hodnotu.
- Monitorování: Informace o tom, že retenční politiky aktivně mažou data, jsou uloženy v interním indexu, aby poskytly referenční bod v případě jakýchkoli problémů.
Ochrana indexu Unparsed: Index unparsed podléhá stejné retenční politice. Vzhledem k tomu, že neparsované logy představují původní, nezpracované originály nezařazených logů, může tento index výrazně růst a může být předmětem dřívějšího smazání.
Žádná granulární retence: V Logmanageru 4.1.x platí retenční politiky globálně na základě diskového prostoru, nikoli pro jednotlivé parsery nebo indexy. Vlastní retenční politiky pro jednotlivé typy logů jsou plánovány pro budoucí vydání.
Doporučení pro monitorování: Pravidelně sledujte využití disku a vzorce růstu indexů, abyste mohli předvídat, kdy mohou retenční politiky začít mazat data dříve, než je žádoucí. Pokud je tlak na disk častý, zvažte rozšíření úložné kapacity nebo optimalizaci zdrojů logů.